
I think every programmer tries to automate some of their tasks. Once, one of my colleagues created an app that checked the cinema website in order to book a ticket to a Star Wars movie.
In C# the are many ways to scrape a website or automate a flow on a website. Here is a list of possible options:
Selenium Webdriver
Selenium is an automation testing framework that can be also used to record human actions on websites.
It’s the most popular choice for website automation.
I don’t recommend using it for scraping, but it’s useful for dynamic pages. If you have a page where the information is hidden behind a button click, then Selenium might be a choice.
Selenium offers the possibility to control a real browser. It has by default support for Chrome, Internet Explorer, Firefox, and a headless browser that doesn’t offer a visual window.
A headless browser is useful because it doesn’t need so much RAM memory.
Puppeteer Sharp
Puppeteer is similar to Selenium. This means that in the back an actual browser loads the pages.
In my opinion, Puppeteer is more powerful for the automation of the UI than Selenium. It also offers the possibility to create PDF files based on the results.
Puppeteer is easier to learn than Selenium. Look for example, how easy is to take a screenshot of this blog.
using var browserFetcher = new BrowserFetcher();
await browserFetcher.DownloadAsync();
await using var browser = await Puppeteer.LaunchAsync(
new LaunchOptions
{
Headless = false,
ExecutablePath= @"C:\Program Files\Google\Chrome\Application\chrome.exe",
IgnoredDefaultArgs = new string[] { "--disable-extensions" }
});
await using var page =(await browser.PagesAsync())[0];
await page.GoToAsync("http://programmingcsharp.com");
await page.ScreenshotAsync("screenshot.png");
Web Browser in Windows Forms
This is a recommended way to automate browser actions and offer an enhanced view of the actions in your Windows Form or WPF Application.
There are multiple web browser instances that can be used in the Windows Forms framework.
WebBrowser2 Control Class
In the Windows Forms framework, there is a default control that gives you a web browser in your form. This web browser can be controlled.
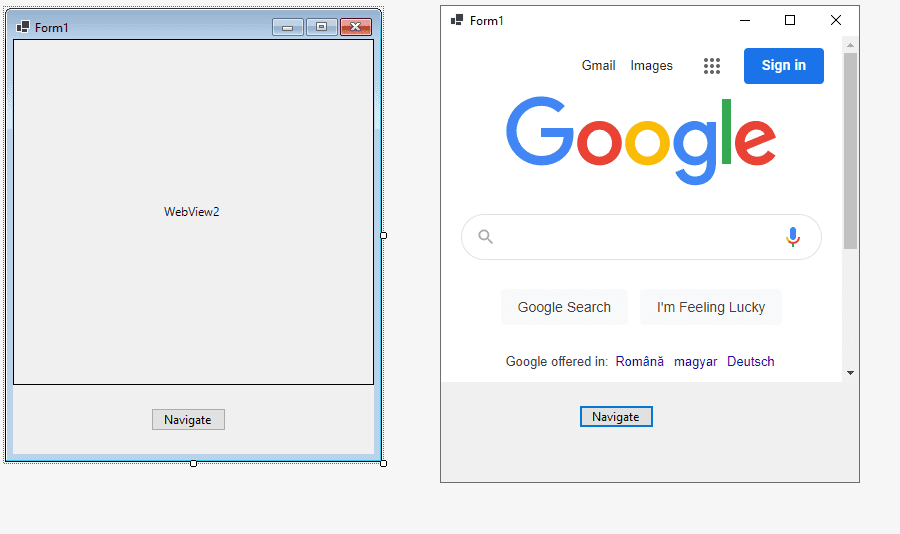
You can navigate to a website, find the text boxes by using a selector, fill out the form and submit it.
private async void button1_Click(object sender, EventArgs e)
{
this.webView21.Source= new Uri("https://programmingcsharp.com");
await webView21.ExecuteScriptAsync("document.querySelector(\"input[value = 'Sign up']\").click();");
}
In this way, you can automate some actions directly from your form.
I recommend you start with this tutorial to get started with WebView2 in your Windows Form Application.
CefSharp – Embedded Chromium browser
CefSharp is an open-source library and it lets you embed a Chromium browser in your Windows Form Application or WPF.
It’s very similar to WebView2 control. It has support for 32-bit and 64-bit CPUs.
HTML Agility Pack
HTML Agility Pack is a .NET library that can load HTML pages and parse them.
Once you loaded the HTML, you can use XPATH to select the information that you need. There is also the possibility to use CSS selectors or other HTML attributes.
In conjunction with LINQ, you can traverse the document, and browse through the document.
The HTML Agility Pack library offers a lot of helper methods in order to help you to manipulate the DOM.
In my opinion, this is the best choice if you want to scrape the Internet using C#.
Look for example how easy is to read the headers from my blog:
HtmlWeb web = new HtmlWeb();
var htmlDoc = web.Load("https://programmingcsharp.com");
var nodes = htmlDoc.DocumentNode.SelectNodes("//body//h2");
foreach (var node in nodes)
{
Console.WriteLine(node.InnerText);
}
AngleSharp
AngleSharp is a library that can be used to parse HTML, CSS, XML, or JavaScript.
It’s very similar to Html Agility Pack, which is considered more popular.
After you load the HTML source code, you can use LINQ on the document object. So, it’s easy to find your desired information.
var config = Configuration.Default.WithDefaultLoader(); var address = "https://programmingcsharp.com"; var context = BrowsingContext.New(config); var document = await context.OpenAsync(address); var headers = "body h2"; var cells = document.QuerySelectorAll(headers); var titles = cells.Select(m => m.TextContent);
AngleSharp can handle SVG and MathML elements.
RestSharp
RestSharp is a REST API client.
REST is a protocol that many big websites use in order to expose their data and features. For example, you can get the Twitter profile avatar by calling a REST API.
Every time when you want to get some data from a website, search first for REST services. If there are some public services available, then use them.
Many websites offer a REST API in order to avoid scrapers that overload the servers. An API will return only the needed data without overhead like HTML and CSS.
Iron Web Scraper
Iron Web Scraper is a product that allows you to scrape websites.
The difference between this product and other open-source projects is that Iron Software has a suite of products that can help you to automate things:
- PDF – create, read and edit PDF files
- Iron OCR – Optical Character Recognition that supports multiple languages and formats
- Iron XL – automate Microsoft Office Excel
- Iron Barcode – read and write QR and barcodes
Conclusions about C# automation
There are many other tools that you can use to automate things. If none doesn’t fit your needs, then feel free to create your own tool.
Take a look at HttpClient class, it is the basic class that can perform HTTP requests. You can download the source code and use a library like AngleSharp to parse the HTML.
On the part, if you want to create bots for some websites, first, try to search if they offer a public service for their features. Some websites give you for free a lot of data.
In conclusion, take a look at different possibilities and then choose one or multiple libraries.
HtmlAgilityPack doesn’t work for a lot of websites as it doesn’t run Javascript. So a headless browser would work better for those.